목차
https://azure.microsoft.com/ko-kr/products/machine-learning
공공 데이터 포털 사용하기
https://eunchankim-dev.tistory.com/16
[Data Science] 공공데이터 사이트 모음(국내 사이트, 해외 사이트)
빅데이터 시대에서 데이터는 하나의 중요한 자산이 되었습니다. 데이터를 파는 회사도 생겨나고 데이터를 구입해 분석한 결과를 판매하는 회사도 생겨나고 있습니다. 데이터를 개인이 직접 수
eunchankim-dev.tistory.com
https://www.kaggle.com/datasets
Find Open Datasets and Machine Learning Projects | Kaggle
Download Open Datasets on 1000s of Projects + Share Projects on One Platform. Explore Popular Topics Like Government, Sports, Medicine, Fintech, Food, More. Flexible Data Ingestion.
www.kaggle.com
https://datasetsearch.research.google.com/
Dataset Search
datasetsearch.research.google.com
XML parsing
import xml.etree.ElementTree as et
xmlstr='''
<stus>
<stu><num>1111</num><name>user1</name></stu>
<stu><num>2222</num><name>user2</name></stu>
<stu><num>3333</num><name>user3</name></stu>
<stu><num>4444</num><name>user4</name></stu>
</stus>
'''
stus=et.fromstring(xmlstr)type(stus),stus.tagfor stu in list(stus):
print(stu.tag)
info=list(stu)
print('{}학번 이름:{}'.format(info[0].text,info[1].text))
print(stu.findtext('num'),stu.findtext('name'))gdown을 이용한 io 작업 - json 파일 저장하기

import gdown
gdown.download('https://bit.ly/3q9SZix','download1.json',quiet=False)
pandas로 json 파일 읽어오기
import pandas as pd
df=pd.read_json('download1.json')
df.head()
books=df[['no','ranking','bookname','authors']]
books.head()
# books.loc[:3,'ranking':'authors']
books.iloc[:3,::2]
books=df[['no','ranking','bookname','isbn13']]
top4=books.loc[:4,:]url로 web scraping 하기
url='http://www.yes24.com/Product/Goods/{}'.format(74261416)
msg=requests.get(url).textsoup=BeautifulSoup(msg,'html.parser')
detail=soup.find('div',attrs={'id':'infoset_specific'})
detail
for tr in detail.find_all('tr'):
if tr.th.get_text()=='쪽수, 무게, 크기':
print(tr.find('td').get_text().split(' | ')[0])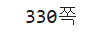
def get_page_cnt(isbn):
url='http://www.yes24.com/Product/Goods/{}'.format(isbn)
msg=requests.get(url).text
soup=BeautifulSoup(msg,'html.parser')
detail=soup.find('div',attrs={'id':'infoset_specific'})
if detail==None:
return ''
for tr in detail.find_all('tr'):
print(url)
print(msg)
print(soup)
print(detail)
if tr.th.get_text()=='쪽수, 무게, 크기':
return tr.find('td').get_text().split(' | ')[0]
return ''
def get_page_cnt2(row):
su=row['isbn13']
get_page_cnt(su)
def get_isbn13(row):
return row['isbn13']row=top4.apply(get_isbn13,axis=1)
pd.merge(top4,pd.DataFrame(row),left_index=True,right_index=True)
# pd.concat([top4,row],axis=1)
'100일 챌린지 > 빅데이터기반 인공지능 융합 서비스 개발자' 카테고리의 다른 글
| Day 90 - Regression (0) | 2024.12.05 |
|---|---|
| Day 89 - scikit-learn (0) | 2024.12.04 |
| Day 89 - web scraping (2) (0) | 2024.12.04 |
| Day 88 - web scraping (1) (0) | 2024.12.03 |
| Day 88 - Numpy, pandas, matplotlib (0) | 2024.12.03 |