목차
load_breast_cancer
Gallery examples: Post pruning decision trees with cost complexity pruning Model-based and sequential feature selection Permutation Importance with Multicollinear or Correlated Features Effect of v...
scikit-learn.org
데이터 전처리
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
data.target[[10, 50, 85]]
list(data.target_names)
data.data
data.feature_names
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltX=pd.DataFrame(data.data,columns=data.feature_names)
y=data.targetX.corr()
X.describe()
Decision tree 분류 모델
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y)from sklearn.tree import DecisionTreeClassifier
model=DecisionTreeClassifier()
model.fit(X_train,y_train)
model.score(X_test,y_test)
pd.DataFrame(model.feature_importances_,index=data.feature_names)
재현율, 정확도, 정밀도 구하기
from sklearn.metrics import accuracy_score,recall_score,precision_score,f1_score
print('정확도:',accuracy_score(y_test,model.predict(X_test)))
print('재현율:',recall_score(y_test,model.predict(X_test)))
print('정밀도:',precision_score(y_test,model.predict(X_test)))
print('f1 스코어:',f1_score(y_test,model.predict(X_test)))
voting
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.ensemble import VotingClassifier
model1=DecisionTreeClassifier()
model2=LogisticRegression(max_iter=10000)
model3=KNeighborsClassifier()
voting=VotingClassifier(
estimators=[('DT',model1),('LR',model2),('KN',model3)],
voting='hard' #'soft'
)
voting.fit(X_train,y_train)
voting.score(X_test,y_test)
# voting.predict_proba(X_test)
for model in voting.estimators_:
print(model.score(X_test,y_test))
bagging
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
model=RandomForestClassifier()
option={
'n_estimators':[100,200,300],
'max_depth':[3,5,7],
'min_samples_split':[2,3,5],
'n_jobs':[-1],
}
gs_cv=GridSearchCV(model,option)
gs_cv.fit(X_train,y_train)
gs_cv.score(X_test,y_test)
gs_cv.best_params_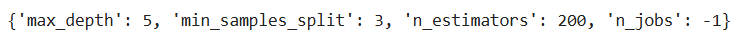
gs_cv.best_estimator_
data.feature_names[gs_cv.best_index_]
gs_cv.best_score_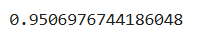
top10=pd.Series(gs_cv.best_estimator_.feature_importances_,index=gs_cv.feature_names_in_).sort_values(ascending=False).head(10)
top10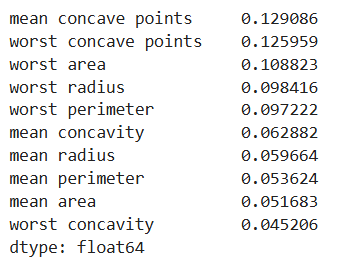
plt.barh(width=top10,y=top10.index)
boosting
Ada Boost
from sklearn.ensemble import AdaBoostClassifier
model=AdaBoostClassifier(algorithm='SAMME')
model.fit(X_train,y_train)
model.score(X_test,y_test)
Gradient Boost
from sklearn.ensemble import GradientBoostingClassifier
model=GradientBoostingClassifier()
model.fit(X_train,y_train)
model.score(X_test,y_test)
XG Boost

from xgboost import XGBClassifier
model=XGBClassifier()
model.fit(X_train,y_train)
model.score(X_test,y_test)
'100일 챌린지 > 빅데이터기반 인공지능 융합 서비스 개발자' 카테고리의 다른 글
| Day 91 - Tensorflow (0) | 2024.12.06 |
|---|---|
| Day 91 - 비지도 학습 (0) | 2024.12.06 |
| Day 90 - Softvector Machine (0) | 2024.12.05 |
| Day 90 - Regression (0) | 2024.12.05 |
| Day 89 - scikit-learn (0) | 2024.12.04 |