목차

CNN
from tensorflow.keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as pltlen(mnist.load_data()[0][0][0])
plt.imshow(mnist.load_data()[0][0][0])
len(mnist.load_data()[0][0]),len(mnist.load_data()[0][1]),len(mnist.load_data()[1][0]),len(mnist.load_data()[1][1]),
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print("x_train shape", x_train.shape)
print("y_train shape", y_train.shape)
print("x_test shape", x_test.shape)
print("y_test shape", y_test.shape)
X_train = x_train.reshape(60000, 784)
X_test = x_test.reshape(10000, 784)X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255from tensorflow.keras.utils import to_categorical
print(y_train.shape,y_test.shape)
y_train=to_categorical(y_train)
y_test=to_categorical(y_test)
print(Y_train.shape,y_test.shape)
y_train[0]
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense, Input
model = Sequential()
model.add(Input(shape=(784,)))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dense(10))
model.add(Activation('softmax'))
model.summary()
# model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
from tensorflow.keras.losses import categorical_crossentropy
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import CategoricalAccuracy,categorical_accuracy
model.compile(loss=categorical_crossentropy,optimizer=Adam(),metrics=[categorical_accuracy])# model.fit(X_train, y_train, batch_size=128, epochs=10, verbose=1)
model.fit(X_train, y_train, batch_size=256, epochs=10, verbose=1)
model.save('mnist.h5')
score = model.evaluate(X_test, y_test)
print('Test score:', score[0])
print('Test accuracy:', score[1])
predicted_classes = np.argmax(model.predict(X_test), axis=1)
correct_indices = np.nonzero(predicted_classes == mnist.load_data()[1][1])[0]
incorrect_indices = np.nonzero(predicted_classes != mnist.load_data()[1][1])[0]print('predicted classes: ',predicted_classes)
print('correct indices: ',correct_indices)
print('incorrect indices: ',incorrect_indices)
plt.figure()
for i in range(9):
plt.subplot(3,3,i+1)
correct = correct_indices[i]
plt.imshow(X_test[correct].reshape(28,28), cmap='gray')
plt.title("Predicted {}, Class {}".format(predicted_classes[correct], mnist.load_data()[1][1][correct]))
plt.tight_layout()
plt.figure()
for i in range(9):
plt.subplot(3,3,i+1)
incorrect = incorrect_indices[i]
plt.imshow(X_test[incorrect].reshape(28,28), cmap='gray')
plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], mnist.load_data()[1][1][incorrect]))
plt.tight_layout()
커스텀 데이터로 모델 만들기
X=np.array([-50,-40,-30,-20,-10,0,10,20,30,40,50])
y=np.array([0,0,0,0,0,0,1,1,1,1,1])from tensorflow.keras.losses import BinaryCrossentropy
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.metrics import BinaryAccuracy
model=Sequential()
model.add(Input(shape=(1,)))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss=BinaryCrossentropy, optimizer=SGD(), metrics=[BinaryAccuracy])model.fit(X,y,epochs=200)
model.predict(np.array([1,2,3,4,5]))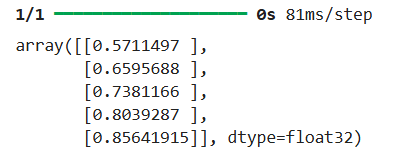
from sklearn.datasets import load_irisiris=load_iris()X=iris.data
y=iris.targetfrom sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y)X_train.shape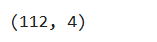
y_train=to_categorical(y_train)
y_test=to_categorical(y_test)model=Sequential()
model.add(Input(shape=(4,)))
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(loss=categorical_crossentropy,optimizer=Adam(),metrics=[categorical_accuracy])model.fit(X_train,y_train,epochs=10)
model.save('iris_cnn.h5')
# model.export('model/iris_cnn.h5')
from tensorflow.keras.models import load_model
new_model = load_model('iris_cnn.h5')
model.evaluate(X_test,y_test)
new_model.evaluate(X_test,y_test)
np.argmax(model.predict(X_test),axis=1)
np.argmax(y_test, axis=1)
RNN
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import math
import numpy as np
import matplotlib.pyplot as plt
from pandas import read_csv!git clone https://github.com/yhlee1627/deeplearning.git
dataframe = read_csv('deeplearning/corona_daily.csv', usecols=[3], engine='python', skipfooter=3)
print(dataframe)
dataset = dataframe.values
dataset = dataset.astype('float32')
scaler = MinMaxScaler(feature_range=(0, 1))
Dataset = scaler.fit_transform(dataset)
train_data, test_data = train_test_split(Dataset, test_size=0.2, shuffle=False)
print(len(train_data), len(test_data))
def create_dataset(dataset, look_back):
x_data = []
y_data = []
for i in range(len(dataset)-look_back-1):
data = dataset[i:(i+look_back), 0]
x_data.append(data)
y_data.append(dataset[i + look_back, 0])
return np.array(x_data), np.array(y_data)
look_back = 3
x_train, y_train = create_dataset(train_data, look_back)
x_test, y_test = create_dataset(test_data, look_back)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
x_train.shape,y_train.shape
X_train = np.reshape(x_train, (x_train.shape[0], 1, x_train.shape[1]))
X_test = np.reshape(x_test, (x_test.shape[0], 1, x_test.shape[1]))
print(X_train.shape)
print(X_test.shape)
from tensorflow.keras.layers import Input
from tensorflow.keras.metrics import MSE,R2Score
model = Sequential()
model.add(Input(shape=(1, look_back)))
model.add(SimpleRNN(3))
model.add(Dense(1, activation="linear"))
model.compile(loss='mse', optimizer='adam',metrics=[MSE,R2Score])
model.summary()
model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=1)
trainPredict = model.predict(X_train)
testPredict = model.predict(X_test)
TrainPredict = scaler.inverse_transform(trainPredict)
Y_train = scaler.inverse_transform([y_train])
TestPredict = scaler.inverse_transform(testPredict)
Y_test = scaler.inverse_transform([y_test])
trainScore = math.sqrt(mean_squared_error(Y_train[0], TrainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(Y_test[0], TestPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[look_back:len(TrainPredict)+look_back, :] = TrainPredict
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(TrainPredict)+(look_back+1)*2:len(dataset), :] = TestPredict
plt.plot(dataset,'r')
plt.plot(trainPredictPlot,'g')
plt.plot(testPredictPlot,'b')
plt.legend()
plt.show()
'100일 챌린지 > 빅데이터기반 인공지능 융합 서비스 개발자' 카테고리의 다른 글
| Day 92 - 머신러닝을 활용하는 웹 서비스 만들기 (1) | 2024.12.09 |
|---|---|
| Day 91 - Tensorflow (0) | 2024.12.06 |
| Day 91 - 비지도 학습 (0) | 2024.12.06 |
| Day 91 - 앙상블(Ensamble) 사용하기 (0) | 2024.12.06 |
| Day 90 - Softvector Machine (0) | 2024.12.05 |